1. 指针的基础知识
1.1 指针的基本语法
与指针操作相关的运算符: 解引用运算符*, 取地址运算符&
指针最基础的语法如下:
1 | //操作1 |
对比以上两种操作
指针用于存储地址, 通过地址可以找寻到该地址处的数据, 或者以该地址为起始地址的数据.
1.2 指针的简单应用
如何实现交换两个数的内容:
1 | include <stdio.h> |
以上是基本的交换两个数的实现, 这样写完全没问题. 如果我有10000个这样的数需要交换, 不可能写一万遍代码吧? 很自然的想到, 使用函数, 把重复使用的代码提取成一个函数.
那么如何写呢?
1 | void swap(char a, char b) |
好了这个函数实现了
接下来在主函数调用一下:
1 | include <stdio.h> |
在这里给出输出
可以看出输出不对, 盒子里的球并没有被交换
为什么会这样?
原因在与swap函数
函数的形式参数和实际参数
对于函数的参数:
在声明和定义时写在函数参数列表中的参数是形式上的参数, 起到占位置的作用, 所以叫形式参数, 简称形参.
形参在你调用函数时告诉你这里应当填什么样的数据.
在调用函数时, 写入到参数列表的参数才是实际用到的参数, 称为实际参数, 简称实参.
在这里, 我们把两个参数传入其中, 只是在形参之间换来换去, 没有影响到实参.
试想一下, swap这个机器, 伸出两只机械臂, 要求你把篮球和足球放上去, 于是你另外拿了两个球给它, 它把球左手倒右手一换, 对你手上两个的盒子和其中的内容却没有任何影响.
请注意, 我们的要实现交换两个球的目的, 不只要关心这两个球之间的关系, 还要关心球与盒子之间的关系, 一共是四个元素而不是两个元素.
那么有没有一种东西, 既可以操作盒子, 又可以操作盒子中的内容呢?
你好, 有的, 兄弟, 有的! 看一下指针吧, 兄弟!
指针本体可以操作盒子, 通过解引用操作可以操作盒子内的物品, 两个要求, 一次满足, 简直太完美了.
于是就可以实现一个新的swap函数:
1 | void new_swap(char * a, char * b) |
2. 指针和内存空间
2.1 不同类型数据占据的存储空间
为了合理的存储不同大小的数据, 既不浪费, 也不溢出, 有不同数据类型.
为了应对不同的数据类型, 指针也有了不同的类型. 但是指针的类型和数据类型有一些区别.
我们知道, 不同数据类型的本质区别就是占据的空间大小不同.
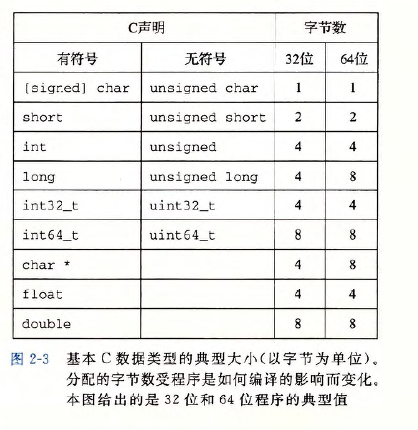
(此处给出数据类型大小表格)
我们使用sizeof()运算符可以计算数据的大小, sizeof的用法类似函数(但它实际上不是参数而是运算符), 括号中传入参数, 返回一个数字(该返回值的类型为size_t) 表示传入的参数的占据空间大小, 以字节为单位.
1 | printf("size of char:%d",sizeof(char)); |
照这样来看数组应该根据存储数据类型的不同, 拥有不同的大小, 然而事实却不是这样. 一般来说, 指针拥有固定的大小.
原因也很简单, 指针存储的是地址, 所有的地址都是同一类型的数据, 不论是char还是int, 都是地址. 所以占据的大小都是相同的.
那么可以说所有的指针都是同一类型的数据吗?
当然不能.
虽然指针本身所占的空间大小相同, 但其中包含的地址所指向的数据本身却是不同的.
1 | char * char_ptr; |
以上的数据声明中, 有char *, short *, int * 三种不同类型的数据, 可以这样理解, 其中的*(解引用运算符)表示这三者都是指针, 而char, short, int表示其中存储的数据的不同类型. 这两个方面的信息共同构成了指针的类型.
当计算机根据指针中存储的地址找到所在位置之后, 通过声明指针变量是给出char, int或其他数据类型的信息决定取一个字节或四个字节的数据.
void 类型 和void* 类型
void 类型 和void* 类型void 表示无类型,不能直接用来定义变量,如void x=0;这条语句是不合法的。用在函数头的返回值或参数列表中,表示函数无参或无返回值。如void func(void),表示一个既无参数有无返回值的函数。
void*表示无类型指针,可以用来定义变量,void* ptr=&x;该语句是合法的。void*是为了满足一些函数的适配性而设计的(即泛型编程),例如,设计一个函数long sumof(int a,int b)用于计算两个数之和,因为不能确定要计算的两个数的大小,如果给出的参数超出了int类型的限制就会产生意想不到的结果。将其修改为void* sumof(void* a,void* b,DATA_TYPE type),不论数据有多大,先接受了再说,同时传入数据类型,根据数据类型,在函数中采用不同的处理方式即可。
为何void不可以直接用于定义变量而void*可以?
void*归根到底是一个指针,用该类型定义变量编译器知道用多少内存来存储该变量,因为一台机器上的指针类型大小是固定的。而对于void类型的变量,编译器不知道该使用多大的内存来存储,因此无法直接定义变量。相应的,由于void*类型没有数据类型,因此不能直接对void*指针直接解引用,也不能直接使用++运算符。例如,语句int a=0; void* ptr = &a; b=*ptr和void* ptr=&a; ptr++;都是不合法的。
2.2 寻址空间和指针大小
我们知道指针的大小一般都是相同的,那么会是多大呢?可以使用sizeof()运算符测算
1 | int a=10; |
大部分情况下, 结果都会是8. 这表示指针类型占据8字节空间大小.
指针占据的空间是由CPU的寻址位数所决定的, CPU的寻址位数决定了其能够访问的内存地址的范围,也决定了指针变量能够存储的地址值的位数。例如,在32位机器上,地址是由32个0或1的二进制序列组成,因此指针大小通常是4个字节(因为1个字节=8比特位,32比特位=4个字节)。而在64位机器上,地址需要64个0或1的二进制序列组成,因此指针大小通常是8个字节。
当然cpu寻址位数并不是唯一的决定因素, 编译器的编译方式, 虚拟化技术的使用等其他原因可能导致指针大小与实际的CPU不匹配.
cpu的寻址位数, 另一种说法, 也就是cpu的地址总线宽度, 决定了系统的地址空间的大小.
我们在一些软件的release版本中经常能看见x86和x64后缀.
x86是一种32位处理器架构,它广泛被应用于早期的计算机系统中。由于历史原因和广泛的兼容性,许多旧的软件和操作系统仍然基于x86架构。x86架构的处理器能够支持的内存寻址范围为2^32(约4GB),这在一定程度上限制了其在处理大数据和复杂计算任务时的能力。然而,对于许多日常应用和旧版软件来说,x86架构仍然足够满足需求。
相比之下,x64(也称为x86-64或AMD64)是一种64位处理器架构,它提供了更大的内存寻址范围和更高的计算能力。x64架构的处理器能够支持的内存寻址范围为2^64(实际限制通常为16EB,即160亿GB),这使得它能够轻松应对大数据处理和复杂计算任务。此外,x64架构还向下兼容32位应用程序,这意味着用户可以在64位操作系统上运行旧的32位软件。
因此,当软件的release版本后缀带有x86或x64时,这表示该软件分别针对32位或64位的处理器架构进行了优化。用户应该根据自己的操作系统和硬件平台选择合适的版本进行安装。如果你的操作系统是64位的,并且你的计算机硬件支持x64架构,那么建议选择x64版本的软件以获得更好的性能和兼容性。如果你的操作系统或硬件平台是32位的,或者你需要运行一些只能在32位环境下运行的旧版软件,那么你可能需要选择x86版本的软件。
(推书) 汇编语言–王爽
2.3 数据的存储方式
2.3.1 问题的引入
1 | int int_data=0x12345678; |
以上示例输出内容是什么?
在不同的平台上, 输出内容会有差别, 大部分人在PC上应该输出的是0x78, 而在一些特定平台, 则会输出0x12.
原因是什么?
先看看以上操作在干嘛, 定义一个int类型的变量, 取这个变量的地址, 强制类型转换成char*类型的指针, 并通过指针来访问该地址的内容.
还记得我说的指针的类型的含义吗, char * 表示在数组存储的地址上访问sizeof(char) 大小的字节数目(1个字节), int *表示在数组存储的地址上访问sizeof(int) 大小的字节数目(一般为4个字节).
也就是说, 原本的四字节大小的int_data通过这种访问方式被截断为一个字节
在定义时, int_data被赋值为0x12345678, 其中0x表示其后的数据是16进制格式, 也就是说, 刚巧12,34,56,78分别各是一个字节
0x12=0b 0001 0010 , 其他字节内容类似.
接下来就是最关键的问题: 在四个字节的内容被裁剪为一个字节的情况下, 哪个字节会被返回?
2.3.2 字节序和存储模式
从直觉来看, 最开始的12和最末尾的78应该是最有可能的, 结果也是符合直觉的.
再来看一看这个数: 12 34 56 78.
我们读这个数是从12开始, 而这个数的最低位是78, 如果把这个数看成10进制,则 8是个位, 7是十位, 虽然16进制没有个位十位的说法, 但是原理是类似的, 8是最低位, 7是次低位.
78是最低字节(LSB, least significant byte), 相应的, 12是最高字节(MSB, most significant byte). 字节的高低称作字节序
不论一个数是按照十进制还是十六进制, 或是二进制, 八进制等等, 数字总有其排列顺序.
数中的字节讲顺序, 计算机里的存储也讲顺序, 计算机内存按照地址进行编号, 从0开始到虚拟地址空间的最大值, 依次增加, 数据依次存储在其中. 0x1000是低地址, 0x1003是高地址
根据字节序的存储地址不同, 可以分为两种存储模式
- 大端存储:在大端存储模式下,数据的高字节(或称作高位、最重要字节)被存储在内存的低地址处,而数据的低字节(或称作低位、最不重要字节)存储在高地址处。这意味着当你从低地址向高地址读取内存时,数据会按照从高到低的顺序出现。例如,对于十六进制数0x1234,在大端模式下,内存中的布局就是0x12在前(低地址),0x34在后(高地址)。
- 小端存储:在小端存储模式下,数据的低字节存储在内存的低地址处,而高字节存储在高地址处。也就是说,当你从低地址开始读取时,最先读到的是数据的低字节,然后才是高字节。对于相同的十六进制数0x1234,在小端模式下,内存布局会是0x34在前(低地址),0x12在后(高地址)。
于是, 对于0x12345678
- 在大端存储模式下:
int_data的内存布局(从低地址到高地址)将是:0x12,0x34,0x56,0x78。char_ptr指向int_data的第一个字节,即0x12。- 因此,
printf("%x", *char_ptr);将输出12。
- 在小端存储模式下:
int_data的内存布局(从低地址到高地址)将是:0x78,0x56,0x34,0x12。char_ptr指向int_data的第一个字节,即0x78。- 因此,
printf("%x", *char_ptr);将输出78。
因此,该代码在大端存储模式下输出12,在小端存储模式下输出78。
[[C语言指针系列图解.excalidraw]]
使用以下方式可以判断机器是那种存储方式?
1 |
|
注意
你应当注意到了, 不论指针所指向的数据占据的内存空间有多大, 它总是指向数据占据的最低地址, 这一点在数组中也是适用的, 具体会在接下来的3.指针与数组部分详解.
3. 指针和数组
3.1 使用指针操作数组
数组被用来存储一系列相同类型的数据
1 | int a[10]={1,2,3,4,5,6,7,8,9,10}; |
对于数组的基本用法这里不多赘述, 如果不了解建议补充一下基础知识.
我们知道, 数组通过数组下标取数
1 | int x=a[0]; |
取数组的第一个元素赋值给变量x.
然而还有另一种用法, 数组名是一个相应类型的指针.
以上例子中, a可以直接赋值给int *类型的指针使用,且是一个合法地址。该地址是数组第一个元素的地址。
1 | int * int_ptr=a; |
以上写法, 编译既不会报错, 也不会警告. 是合法合规而且经常使用的写法.
于是, 对于数组的元素的访问, 可以有两种不同的方式完成.
1 | int a[10]={1,2,3,4,5,6,7,8,9,10}; |
指针运算
以上代码涉及到一个新的操作:指针运算
仔细观察其中的写法,:*(a+1), 表示a增加“1”, 然后解引用。
一般来说, “加1”操作是直接作用在数值上的,加上1就是数值变大1,但是对于指针来说, 这个1不是大小上的1, 而是单位1.
这里的单位1为指针存储的类型所占的字节数。
之前讲解过, 对于char *,int*等不同类型的指针的含义:
“char * 表示在数组存储的地址上访问sizeof(char) 大小的字节数目(1个字节), int *表示在数组存储的地址上访问sizeof(int) 大小的字节数目(一般为4个字节)”
对于char *类型的数据, 自增以char类型的大小为单位1, 其值就是1个字节.
假设char * char_ptr=0x1000 那么char_ptr+1后, 其值为0x1001. 而如果是int_ptr+1, 其值为0x1004. 其他类型与此相似.
(在这里给出数组数据在内存中的排列)
[[C语言指针系列图解.excalidraw]]
指针运算的这种设计极好的契合了数组操作, 数组各个元素可以直接依照自增取数.
1 | int a[10]={1,2,3,4,5,6,7,8,9,10}; |
以上两种写法都能遍历数组
数组名和指针的区别
看了以上的内容,你可能会认为数组名就是一个指向数组首元素地址的指针,并完全把它当作指针来使用。但数组名不是一个指针,和不能混为一谈。请看如下示例:
1 | >int arr[5]={1,2,3,4,5}; |
以上代码中arr++操作是不合法的,编译报错的意思是说++运算符需要一个左值作为其操作数,虽然数组名是一个左值,但不是一个可以修改的左值。这样是有原因的,数组名作为一个数组的标识(symbol)应该永远指向数组的首地址,不应被任何操作更改,这样才能保证对数组任意元素的正常访问。
那么为什么arr+1这样的操作是合法的?
原因是”+1“操作不会改变arr本身的值,arr+1这样的表达式最终的结果是一个右值,终究是要赋值给某个变量或作为其他运算符的操作数使用。无论是哪种情况,都不会影响arr中存储的值。
3.2 数组到指针的退化
在 C/C++ 中,数组到指针的退化(array-to-pointer decay) 是一个重要的隐式转换机制,它决定了数组名在大多数情况下如何被自动转换为指针。理解这个概念对掌握 C/C++ 的指针和数组操作至关重要。
1. 什么是数组到指针的退化?
- 数组名
arr在大多数表达式中会自动转换为指向其首元素的指针。 - 这种转换是隐式的(编译器自动完成),称为 "退化(decay)"。
- 退化后,数组名
arr不再代表整个数组,而是变成一个指向arr[0]的指针(类型T*,其中T是数组元素的类型)。
示例
1 | int arr[5] = {1, 2, 3, 4, 5}; |
arr原本是一个int[5]类型的数组,但在赋值给p时,它退化为int*类型(指向arr[0])。
2. 何时发生数组到指针的退化?
数组名在以下情况下会退化为指针:
- 作为函数参数传递时:
1 | void func(int *p); // 函数接受指针 |
- 即使函数声明为
void func(int p[5]),p仍然会被当作int*处理(数组语法只是语法糖)。
- 在算术运算(
+,-,++,--)中:
1 | int *p = arr + 1; // arr 退化为指针,然后 +1 运算 |
- 在
[]运算符中:
1 | int val = arr[2]; // 等价于 *(arr + 2) |
- 在比较运算 (
!=,<,>等)中:
1 | if (arr == NULL) { ... } // arr 退化为指针 |
- 在初始化指针时:
1 | int *p = arr; // arr 退化为指针 |
3. 何时不会发生退化?
数组名在以下情况下不会退化为指针,仍然保持数组类型:
-
**
sizeof(arr)**:1
size_t size = sizeof(arr); // 返回整个数组的大小(5 * sizeof(int))
- 如果
arr退化为指针,sizeof(arr)会返回指针的大小(如 4 或 8 字节),而不是数组大小。
- 如果
-
**
&arr(取数组地址)**:1
int (*ptr_to_array)[5] = &arr; // 返回 int(*)[5] 类型(数组指针)
&arr返回的是指向整个数组的指针(int(*)[5]),而不是指向首元素的指针(int*)。
-
字符串字面量初始化字符数组时:
1
char str[] = "hello"; // str 是数组,不会退化为指针
4. 退化后的指针类型
-
如果
arr是T[N]类型(T是元素类型,N是数组大小),则退化后的指针类型是T*。 -
示例:
1
2int arr[5]; // 类型是 int[5]
int *p = arr; // 退化后 p 的类型是 int*
5. 退化与指针算术
由于退化后的 arr 变成 T*,我们可以对它进行指针算术运算:
1 | int arr[5] = {1, 2, 3, 4, 5}; |
arr + i等价于&arr[0] + i,计算的是第i个元素的地址。
6. 退化与多维数组
对于多维数组,退化规则仍然适用,但会逐层退化:
1 | int matrix[3][4]; // int[3][4] 类型 |
- **
matrix退化为int(*)[4]**(指向int[4]的指针)。 - **
matrix[0]退化为int***(指向int的指针)。
示例
1 | int (*p)[4] = matrix; // p 指向 matrix[0](int[4] 类型) |
7. 退化带来的问题
由于退化是隐式的,可能会导致一些意外的行为:
(1) 数组大小信息丢失
1 | void func(int *p) { |
-
解决方案:显式传递数组大小:
1
2void func(int *p, size_t size);
func(arr, sizeof(arr)/sizeof(int));
**(2) 不能对退化后的指针使用 sizeof**
1 | int arr[5]; |
sizeof(arr)返回整个数组的大小,但sizeof(p)返回指针的大小。
8. 如何避免退化?
如果希望保留数组类型(防止退化),可以使用:
-
引用传递(C++):
1
2
3void func(int (&arr)[5]); // 接受 int[5] 类型的引用
int arr[5] = {1, 2, 3, 4, 5};
func(arr); // 不会退化- 这样
sizeof(arr)在函数内部仍然有效。
- 这样
-
使用
std::array(C++):1
2
std::array<int, 5> arr = {1, 2, 3, 4, 5};std::array是 C++ 的容器,不会退化。
9. 总结
| 关键点 | 说明 |
|---|---|
| 什么是退化? | 数组名 arr 在大多数情况下隐式转换为 &arr[0](指针)。 |
| 何时发生? | 函数传参、指针运算、[] 操作、比较运算等。 |
| 何时不发生? | sizeof(arr), &arr, 初始化字符数组时。 |
| 退化后的类型 | T[N] → T*(指向首元素的指针)。 |
| 多维数组退化 | int[3][4] → int(*)[4](指向行的指针)。 |
| 退化的问题 | 丢失数组大小信息,sizeof 行为不同。 |
| 如何避免? | 使用引用(C++)或 std::array(C++)。 |
理解 array-to-pointer decay 能帮助你更好地掌握 C/C++ 的数组和指针操作,避免常见的陷阱! 🚀
3.3 在数组中使用sizeof()
有如下代码示例,尝试运行,看看结果和你想的是否相同:
1 | int arr[5] = {1, 2, 3, 4, 5}; |
继续来看遍历数组的例子
1 | int a[]={2,3,4,2,35,624,546,31,0,46}; |
遍历数组是, for循环的终止条件是数组的长度.
直接在循环中写出数组长度的数字是一种不推荐的写法, 有几个缺点:
- 对于明确给出长度的数组, 我们可以直接知道它的长度, 但对于没有给出长度的数组, 不能一眼看出它的长度.
- 直接在for循环中使用数组长度的数字, 是一种硬编码方式, 如果要改动数组大小, 那么每一个在程序中用到的数组遍历操作都要更改代码, 非常麻烦.
更推荐使用的方法是使用sizeof()运算符:
具体操作如下:
arr_size = sizeof(arr_name)/sizeof(data_type)
sizeof(arr_name)计算数组的所有元素占据的字节数, sizeof(data_type)计算数组每个元素占据的字节数. 两个数一除, 就能算出数组大小.
1 | //使用以上方法遍历数组 |
sizeof和strlen的区别
在以上示例中提到了数组的一个用法: 即使用字符数组存储字符串. 对于这样的字符串既可以使用sizeof()获取其长度, 也可以使用strlen()
来看一下sizeof和strlen的区别:
1. 定义与性质
-
sizeof
- 性质:是C/C++中的一个运算符,用于计算变量或数据类型所占的内存大小。
- 返回值:其返回值是size_t类型,表示某种类型或对象的字节数。
- 计算时机:sizeof是在编译时计算的,而不是运行时,这使得它非常高效。
-
strlen
- 性质:是C语言标准库中的一个函数,用于计算字符串的长度。
- 语法:
size_t strlen(const char *str); - 参数:str表示要计算长度的字符串,以’\0’结尾的字符指针。
- 返回值:返回字符串str的字符数量,不包含’\0’结尾字符。
- 计算时机:strlen的结果是在运行时计算出来的。
2. 使用场景与限制
-
sizeof
- 可以用于数据类型、变量、数组、结构体等,返回它们在内存中的大小,单位是字节。
- 对于数组,sizeof可以直接给出数组所占用的内存大小。但需要注意,当数组作为函数参数传递时,它会被退化为指针,此时使用sizeof来计算数组的大小将返回指针的大小,而不是数组的实际大小。
- 对于指针,sizeof返回的是指针本身的大小,而不是它所指向的内容的大小。
-
strlen
- 只能用于计算以’\0’结尾的字符串的长度。
- 如果字符串没有以’\0’结尾,strlen的行为是未定义的,可能会继续计算直到遇到内存中的某个’\0’字符为止。
- strlen的参数必须是char*类型的指针,不能用于其他数据类型。
3. 示例对比
以下是一个简单的示例,用于说明sizeof和strlen在实际编程中的使用:
1 |
|
在这个示例中,sizeof(str)返回的是数组str所占用的内存大小,包括结尾的’\0’字符;而sizeof(ptr)返回的是指针ptr本身所占用的内存大小,与它所指向的字符串的长度无关。strlen(str)则返回的是字符串str的长度,不包括结尾的’\0’字符。
4. 指针和结构体
4.1 基本用法
使用结构体可以把相关的数据有逻辑的组合在一起, 并通过结构体名称+ .来引用结构体中的变量
1 |
|
可以看出结构体和数组是很像的, 都是用来存储一系列数据的. 二者的区别在于同一结构体中可以包含不同数据类型的数据, 而一个数组中所有数据的数据类型都相同
结构体中也可以包含数组作为其元素, 如上所示, char name[50]是用于存储学生姓名的数组.
通过typedef为结构体起一个别名
1 | //使用typedef定义一个结构体,为其起一个别名 |
4.2 使用指针操作结构体
结构体同样可以通过指针来操作
1 | //使用typedef定义一个结构体,为其起一个别名 |
使用指针同样可以操作结构体成员, 使用指针名+ ->运算符即可.
既然涉及到了指针操作, 那么来看一看结构体在内存中的存储方式吧
1. 结构体的存储方式
结构体在内存中的存储方式是按照其成员变量的声明顺序依次存储的。每个成员变量占用的内存空间取决于其数据类型。例如:
1 | struct Example { |
在没有考虑对齐的情况下,结构体的内存布局大致如下:
-
char a占用1字节。 -
int b占用4字节。 -
short c占用2字节。
因此,结构体的总大小应该是 1 + 4 + 2 = 7 字节。然而,实际的存储方式会受到对齐规则的影响。
2. 结构体的对齐方式
为了提高内存访问效率,编译器通常会对结构体的成员变量进行对齐(alignment)。对齐规则确保每个成员变量的地址是其大小的整数倍。例如,一个4字节的int变量,其地址必须是4的倍数。
2.1 对齐规则
-
成员变量对齐:
-
每个成员变量的起始地址必须是其自身大小的整数倍。例如:
-
char类型的变量对齐要求是1字节对齐。 -
short类型的变量对齐要求是2字节对齐。 -
int类型的变量对齐要求是4字节对齐。 -
long long类型的变量对齐要求是8字节对齐。
-
-
如果成员变量的起始地址不符合对齐要求,编译器会在前面插入填充字节(padding)。
-
-
结构体整体对齐:
-
结构体的总大小必须是其最大成员变量对齐要求的整数倍。例如,如果结构体中最大的成员变量是4字节对齐的,那么整个结构体的大小必须是4的倍数。
-
如果结构体的总大小不符合对齐要求,编译器会在结构体的末尾插入填充字节。
-
3. 示例分析
以之前的结构体为例:
1 | struct Example { |
假设系统的默认对齐规则如下:
-
char:1字节对齐 -
int:4字节对齐 -
short:2字节对齐
3.1 成员变量对齐
-
char a:-
起始地址:0
-
占用1字节,对齐要求是1字节对齐,因此不需要填充。
-
-
int b:-
起始地址:4(下一个4字节对齐的地址)
-
占用4字节,对齐要求是4字节对齐。
-
在
char a和int b之间插入3个填充字节。
-
-
short c:-
起始地址:8(下一个2字节对齐的地址)
-
占用2字节,对齐要求是2字节对齐。
-
3.2 结构体整体对齐
-
结构体的总大小:
1(char)+ 3(填充)+ 4(int)+ 2(short)= 10字节。 -
结构体中最大的成员变量是
int,对齐要求是4字节。 -
因此,结构体的总大小必须是4的倍数。
-
在结构体的末尾插入2个填充字节,使得总大小为12字节。
最终,结构体在内存中的布局如下:
[[C语言指针系列图解.excalidraw]]
| 地址 | 数据 | 说明 |
|---|---|---|
| 0 | char a |
成员变量 |
| 1 | 填充字节 | 对齐int b |
| 2 | 填充字节 | 对齐int b |
| 3 | 填充字节 | 对齐int b |
| 4 | int b |
成员变量 |
| 8 | short c |
成员变量 |
| 10 | 填充字节 | 对齐结构体 |
| 11 | 填充字节 | 对齐结构体 |
结构体的总大小为12字节。
值得注意的是, 改变结构体成员变量的顺序, 结构体大小也会随之改变
1 | //该结构体占据12字节 |
4. 修改对齐方式
C语言允许通过编译器的特定指令或属性来修改结构体的对齐方式。例如,在GCC编译器中,可以使用__attribute__((packed))来禁用填充字节:
1 |
|
在这种情况下,结构体的总大小为7字节,成员变量之间没有填充字节。
5. 对齐方式的意义
-
提高访问效率:
-
对齐的内存访问通常比非对齐访问更快,因为硬件对对齐的内存访问进行了优化。
-
非对齐访问可能会导致额外的内存读取操作,降低性能。
-
-
跨平台兼容性:
- 不同的硬件平台可能有不同的对齐要求。通过明确指定对齐方式,可以确保结构体在不同平台上具有一致的内存布局。
-
节省空间:
- 在某些情况下,禁用对齐(如使用
packed属性)可以节省内存空间,但这可能会牺牲访问效率。
- 在某些情况下,禁用对齐(如使用
6. 总结
C语言结构体的存储方式是按照成员变量的声明顺序依次存储的,但实际的内存布局会受到对齐规则的影响。对齐规则确保每个成员变量的地址是其自身大小的整数倍,并且结构体的总大小是其最大成员变量对齐要求的整数倍。通过理解结构体的对齐方式,可以更好地优化内存使用和提高程序性能。
了解了结构体的存储方式和对齐方式, 可以使用指针自增的方式访问结构体, 偏移合适的大小, 避开填充字节获取有效的信息, 或者直接禁用填充字节.
不过, 并不推荐使用指针自增这种方式访问, 指针类型是固定的, 取出来的数据也是按照指针类型取出, 但结构体中的数据却不全是同一类型, 用这种方法取数非常麻烦. 直接使用指针名 + ->运算符, 简单且直观.
4.3 数组和结构体相互转换
禁用填充字节的结构体与数组直接可以直接相互转化, 不会出现问题.
1 |
|
对于结构体和数组相互转化, 试看如下的应用
如下是某品牌激光雷达开发手册, 其中3.1节 数据包格式中描述了雷达向控制器(计算机)传输的数据包的格式, 并给出了数据结构定义.
如何将原始数据包转化为结构体?
首先使用数组作为接收缓冲区, 数组大小等于两个数据包大小, 数据类型为uint8_t, 也就是char
1 |
|
事实上, 对于任何拥有严格结构限制的数据, 禁用填充字节使用结构体接收, 是一种常见的应用. 如接收通讯协议数据, 接收特定文件格式. 同时也保证代码的可移植性,节省内存空间. 相应的劣势是访问结构体的时间会增加.
5. 函数指针
待续…